—
Prototype of an interactive video installation that uses AI to generate imagery in real-time based on the person’s silhouette that’s standing in front of it. The prompts are either curated and pre-written for a more controlled and predictable experience, or fed in verbally by participants simply speaking them out loud in a microphone for a true free-for-all experience. The microphone gets activated via a body language trigger and the verbal prompt is turned into text using speech-to-text module in real-time.
The AI continuously generates animated video at around 15-20 frames per second using image from camera feed as a visual prompt and combining it with the provided verbal prompt. As the person moves and their body language changes, the generated image follows and reacts to it, creating a real-time magical mirror effect.
why?
AI generated imagery is becoming more prevalent in applications and services around us but the interaction between humans and AI is almost always through writing carefully worded text prompts and having to wait some time to see the visual feedback, resulting in a very slow and unresponsive feedback loop.
This installation lets the users experience interacting with the AI in ways that are much more natural and instinctive to us - through body language, movement and speech. Getting a chance to conjure up an image by simply speaking out loud what’s on your mind or seeing the generated imagery reshape itself in front of you in real-time based on your body language creates an instant feedback loop and a more visceral experience.
The Magic Mirror provides a glimpse of where AI technology could go in the future and how it would feel to control it.
⌨
TouchDesigner, StreamDiffusion, speech-to-text, Kinect camera, 55"+ screen




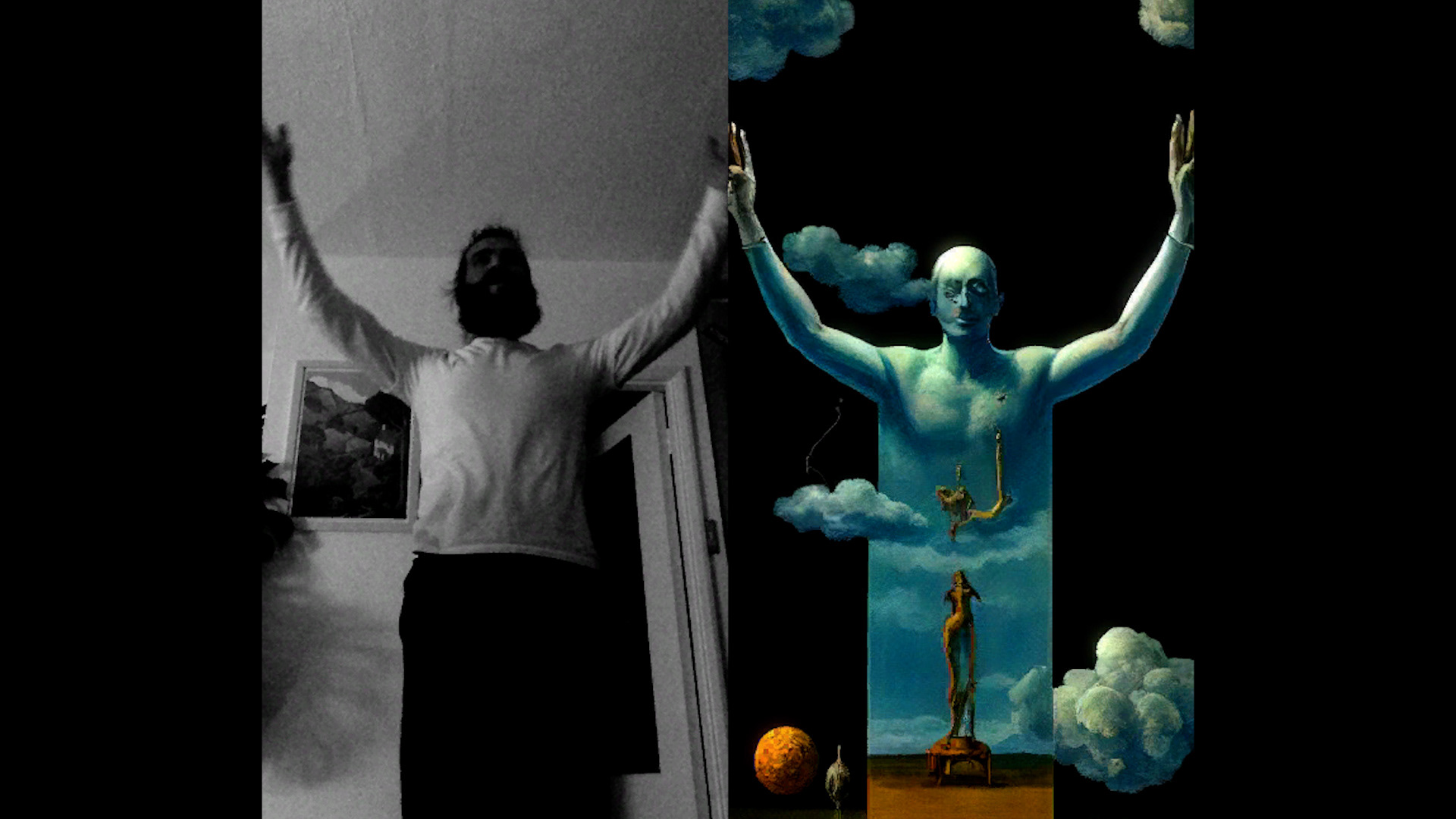



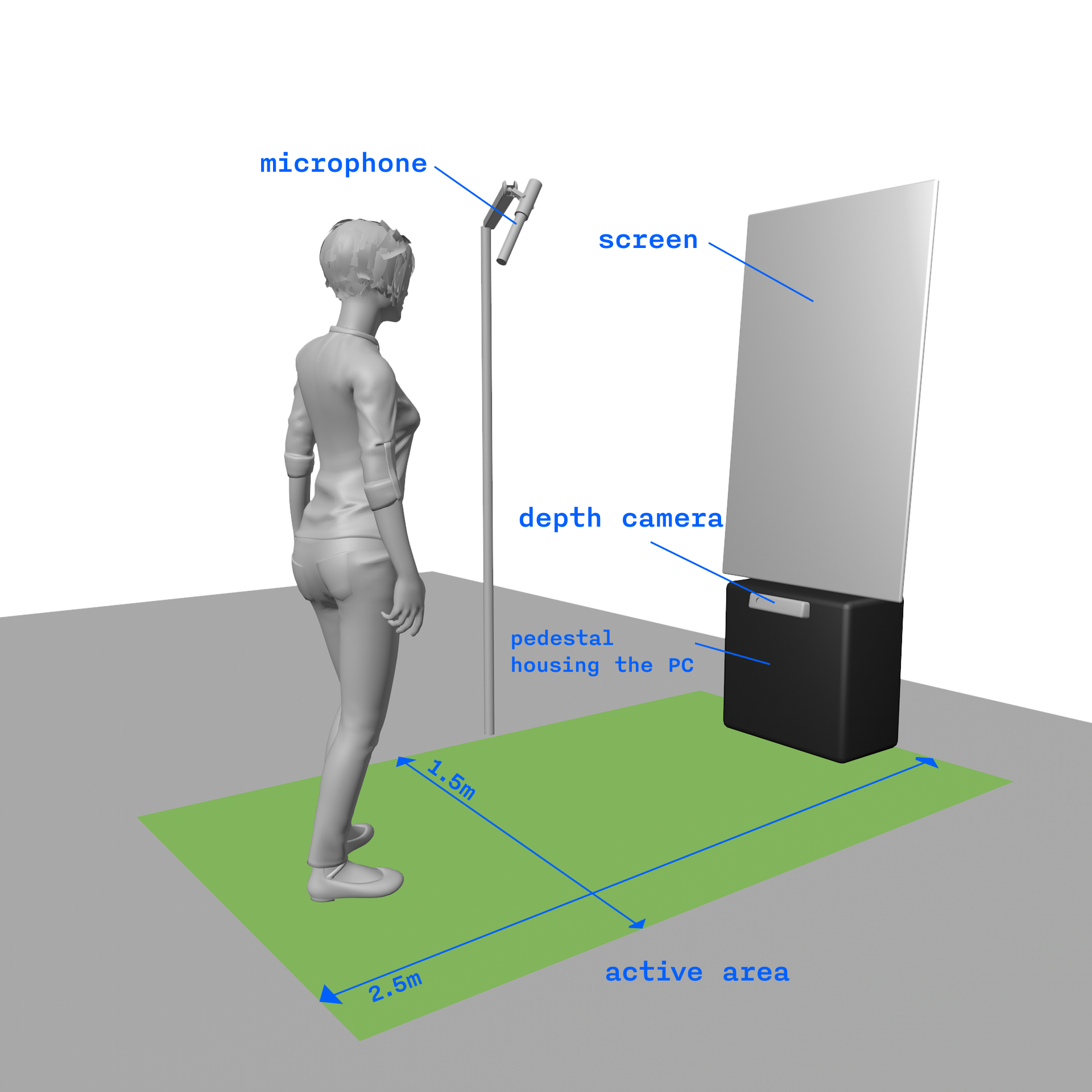
setup ⬎
It works best with participants going in front of the camera one by one or in small groups up to 3 people.
It requires around 2.5x1.5m of floor space and consists of a single 55-75” screen, depth camera, PC with a decent Nvidia graphics card and microphone.
For public spaces where ambient noise is an issue the microphone would be positioned somewhere in the active zone that each participant can speak directly in to, or having a Bluetooth clip-on microphone that gets attached to the active participant. The microphone would come with two push-to-talk buttons to activate it - one would record a new prompt and the other would add to the existing prompt, further facilitating interactivity.
another example →
Using the same core setup to get a different vibe.